从一道题目开始入手Type的一些具体知识,可以想想打印结果是什么?
这里涉及到的是一些golang语言中的Type的一些基础知识,不要再犯迷糊了,好好地加深一下认识~
1 | package main |
从一道题目开始入手Type的一些具体知识,可以想想打印结果是什么?
这里涉及到的是一些golang语言中的Type的一些基础知识,不要再犯迷糊了,好好地加深一下认识~
1 | package main |
Channel有锁还是无锁?
在前面的关于Channel的一些认识当中,我们了解基于无缓存Channels的发送和接收操作将导致两个goroutine做一次同步操作,故无缓存Channels有时候也被称为同步Channels,那么我们就可以使用无缓存的Channel进行简单的goroutine通信了,代码如下:
1 | package main |
这里又可以搬出知乎名言了,在认识一件事物之前,先问问是什么,再回答为什么!直接来说,一个Channel 是一个通信机制,它可以让一个Goroutine 通过它给另一个Goroutine 发送值信息。每个Channel 都有一个特殊的类型,也就是Channels可发送数据的类型(例如:一个可以发送int类型数据的Channel 一般写为chan int)。
在我们常见的一些语言中,多个线程传递数据的方式一般都是共享内存,为了解决线程冲突的问题,我们需要限制同一时间能够读写这些变量的线程数量。而Golang 语言提供了一种不同与使用使用共享内存加互斥锁也能进行通信的并发模型,也就是通信顺序进程(Communicating sequential processes,CSP)。其中Goroutine 和 Channel 分别对应 CSP 中的实体和传递信息的媒介,Go 语言中的 Goroutine 会通过 Channel 传递数据。这也是Golang一直提倡的不要通过共享内存的方式进行通信,而是应该通过通信的方式共享内存。
目前的 Channel 收发操作均遵循了先入先出(FIFO)的设计,而且带缓存区和不带缓存区的 Channel 都会遵循先入先出对数据进行接收和发送(关于带缓存区与不带缓存区在下面会提及),具体规则如下:
通过源码查看我们可知,Channel 在运行时使用 runtime.hchan 结构体进行表示,而这玩意最后包含这一个互斥锁用于保护成员变量,所以从某种程度上说,Channel 是一个用于同步和通信的有锁队列。具体数据结构如下所示:
1 | type hchan struct { |
命令源码文件是程序的运行入口,是每个可独立运行的程序必须拥有的。我们可以通过构建或安装,生成与其对应的可执行文件,后者一般会与该命令源码文件的直接父目录同名。
如果一个源码文件声明属于main包,并且包含一个无参数声明且无结果声明的main函数,那么它就是命令源码文件。 就像下面这段代码:
1 | package main |
这其实就是就简单的可以运行go的一个文件了,刚开始搭建的时候我也是使用这么一段测试代码,随便创建了一个文件之后,然后敲上这么一段代码之后发现控制台可以打印出来“Hello World!”,瞬间感觉就学会了这门语言了,可是事情并没有那么简单,有多难?很难很难。
但是这里让我挺困惑的地方就是,这func main(),没有接收参数入口啊???难道我就只能进行打印了?这不科学,无论在C/C++,还是Java中,main方法都不是这么写的,那么问题就来了,如果进行接收参数呢?
刚接触go的时候很头疼,一下子需要我配置三个环境变量,这三个环境变量看起来很让人头疼,感觉起来三个环境变量的意思大致,区分度不高,这三个环境变量也就是 GOROOT、GOPATH 和 GOBIN。这里简单介绍一下。
其中最让人头疼的就是这个GOROOT,看起来似是而非的感觉,那么GOPATH 有什么意义吗?
这里可以把 GOPATH 简单理解成 Go 语言的工作目录,它的值是一个目录的路径,也可以是多个目录路径,每个目录都代表 Go 语言的一个工作区(workspace)。
我们需要利于这些工作区,去放置 Go 语言的源码文件(source file),以及安装(install)后的归档文件(archive file,也就是以“.a”为扩展名的文件)和可执行文件(executable file)。
这个GOPATH 其实很重要,为什么这么说呢?
因为Go 语言项目在其生命周期内的所有操作(编码、依赖管理、构建、测试、安装等)基本上都是围绕着 GOPATH 和工作区进行的。
前面的Blog介绍了Future接口。这个接口有一个实现类叫FutureTask。FutureTask类有什么用?为什么要有一个FutureTask类?前面说到了Future只是一个接口,而它里面的cancel,get,isDone等方法要自己实现起来都是非常复杂的。所以JDK提供了一个FutureTask类来供我们使用。
FutureTask是Future的具体实现,且实现了Runnable接口,即FutureTask满足了Task的行为,是一个可以被用来执行的Future。FutureTask是JUC提供的线程池实现用到的任务基本单元,线程池主要接收两种对象:一个是Runnable任务,一种是Callable任务。按照ExecutorService接口定义的行为,可以将Runnable或Callable任务提交到线程池执行,而被提交的Runnable或Callable任务都会被包装成FutureTask,由线程池的工作线程去执行。
还有的就是前面的文章中所讲的FutureTask 为什么可以使用Executor 也可以使用线程直接执行?因为FutureTask是实现的RunnableFuture接口的,而RunnableFuture接口同时继承了Runnable接口和Future接口。因此,FutureTask可以交给Executor执行,也可以由调用线程直接执行(FutureTask.run())。
这一部分,我通过一个经典的问题来引出几个线程间通信的方法,即:三个线程如何实现交替打印ABC?
基本思路:使用同步块和wait、notify的方法控制三个线程的执行次序。具体方法如下:从大的方向上来讲,该问题为三线程间的同步唤醒操作,主要的目的就是ThreadA->ThreadB->ThreadC->ThreadA循环执行三个线程。为了控制线程执行的顺序,那么就必须要确定唤醒、等待的顺序,所以每一个线程必须同时持有两个对象锁,才能进行打印操作。一个对象锁是prev,就是前一个线程所对应的对象锁,其主要作用是保证当前线程一定是在前一个线程操作完成后(即前一个线程释放了其对应的对象锁)才开始执行。还有一个锁就是自身对象锁。主要的思想就是,为了控制执行的顺序,必须要先持有prev锁(也就前一个线程要释放其自身对象锁),然后当前线程再申请自己对象锁,两者兼备时打印。之后首先调用self.notify()唤醒下一个等待线程(注意notify不会立即释放对象锁,只有等到同步块代码执行完毕后才会释放),再调用prev.wait()立即释放prev对象锁,当前线程进入休眠,等待其他线程的notify操作再次唤醒。
下面程序可以看到程序一共定义了a,b,c三个对象锁,分别对应A、B、C三个线程。A线程最先运行,A线程按顺序申请c,a对象锁,打印操作后按顺序释放a,c对象锁,并且通过notify操作唤醒线程B。线程B首先等待获取A锁,再申请B锁,后打印B,再释放B,A锁,唤醒C。线程C等待B锁,再申请C锁,后打印C,再释放C,B锁,唤醒A。看起来似乎没什么问题,但如果你仔细想一下,就会发现有问题,就是初始条件,三个线程必须按照A,B,C的顺序来启动,但是这种假设依赖于JVM中线程调度、执行的顺序。
JDK1.6 之后 Synchronized 的实现引入了大量的优化,如偏向锁、轻量级锁、自旋锁、适应性自旋锁、锁消除、锁粗化等技术来减少锁操作的开销。锁主要存在四中状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。
Java中的synchronized 的偏向锁、轻量级锁、重量级锁三种形式,分别对应了锁只被一个线程持有、不同线程交替持有锁、多线程竞争锁三种情况。当条件不满足时,锁会按偏向锁->轻量级锁->重量级锁 的顺序升级。JVM种的锁也是能降级的,只不过条件很苛刻,可以相当于没有了,策略是为了提高获得锁和释放锁的效率。
所以对Synchronized 的重点分析应该是其升级流程,以前是我觉得So easy,不就这几个状态升上去而已,不过在某天看了 死磕Synchronized底层实现 之后,发现我还是太嫩了,这才是真正的深入,也许对知识的求知就该如此不断的进行深入,对于Synchronized 还是有很多值得发现的知识,以下记录了学习到的一些笔记,大概对一整个锁的升级流程有了一些认识和了解。
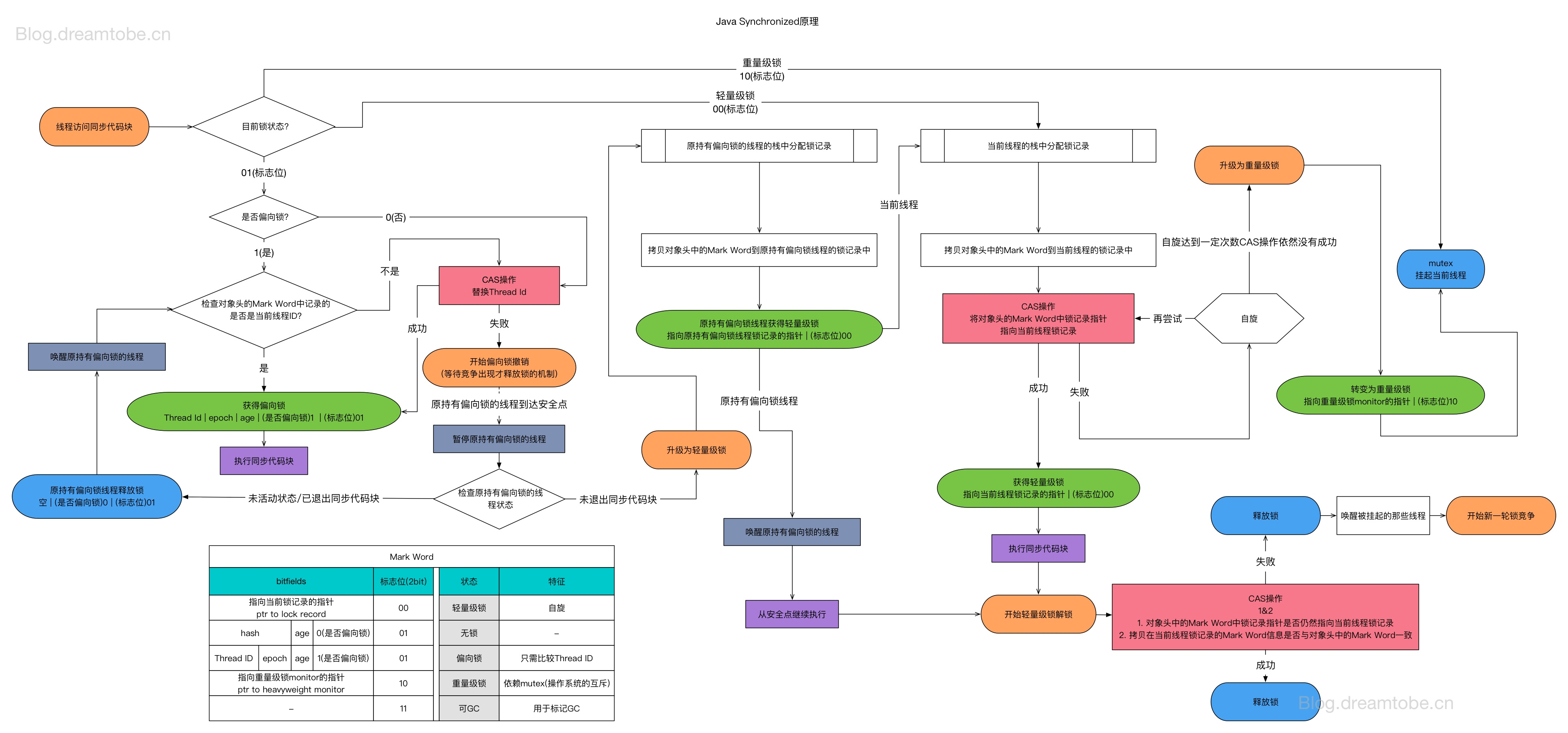
我们前面已经 Synchronized 在JDK1.6 进行哪一些方面的优化,通过这些底层的优化之后Synchronized 变得好用了很多,那么它究竟和其他锁机制有什么差别?换种方式说,我在进行编程的过程中,究竟要如何进行选择?什么时候应该选择Synchronized?而什么时候不选用Synchronized而选用其他的锁机制。
总感觉学习了Synchronized之后,对于其内部原理熟悉了,不知道有没有其他人跟我一样困惑,我究竟该何时进行使用它呢?在哪个场景下我该第一时间想到这货?我觉得进行选择还应该先进行对比,将和我们之前学习到的一些同步机制进行联系起来,有对比才有总结,尽量多进行比较,多点思考,才有更深入的理解与认识。