1.概括
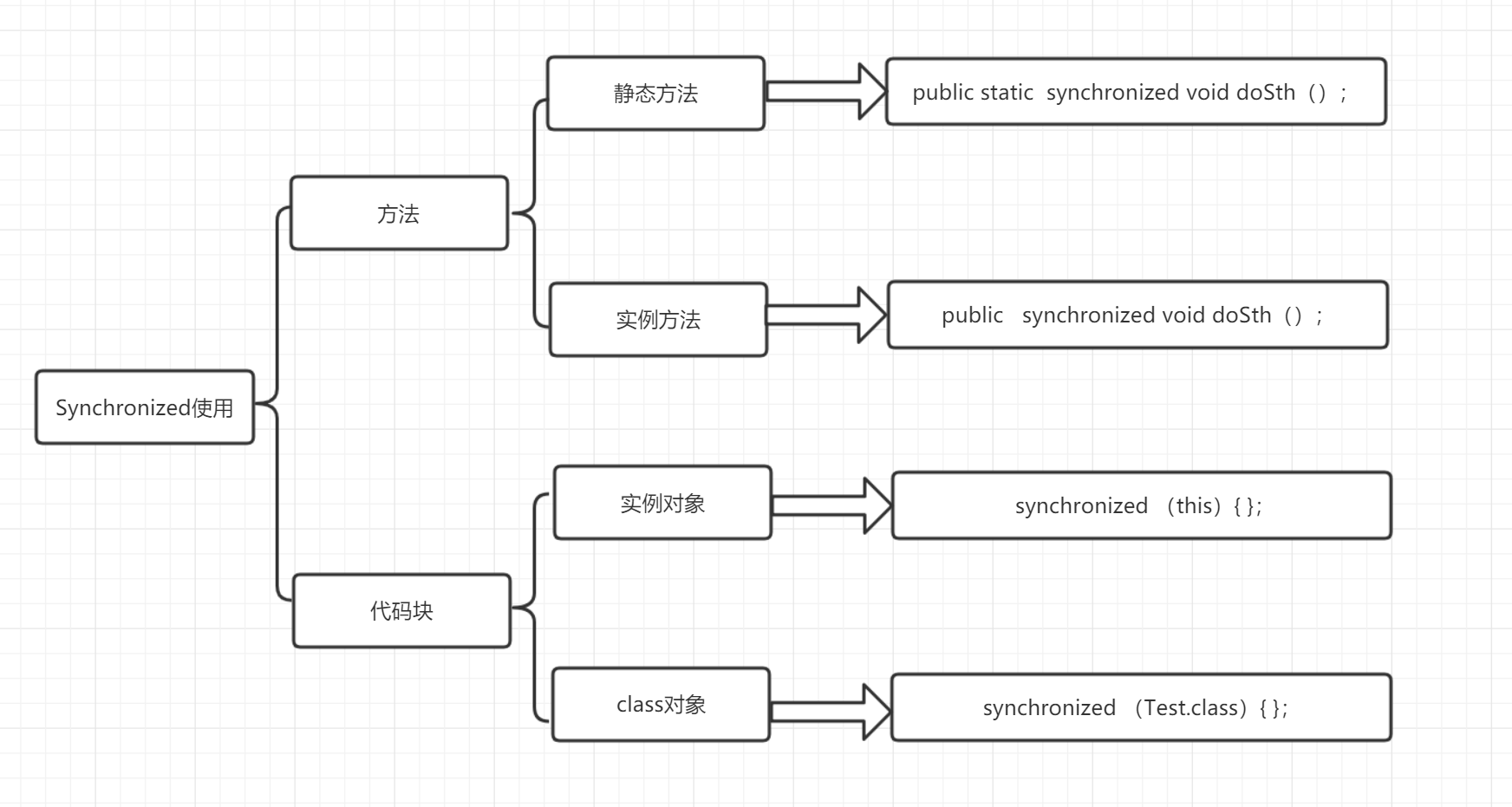
Synchronized 可以有几种修饰方法,总体使用如下图所示:
什么是CAS?
CAS,全称:Compare and Swap,即比较-替换;CAS是一种无锁算法,通过无锁的方式实现了多个线程间变量的同步;CAS 是乐观锁的一种实现方式,是一种轻量级锁,JUC 中很多工具类的实现就是基于 CAS 的。
注意:JVM中的CAS操作正是利用了处理器提供的CMPXCHG指令实现的。
具体内容:
假设有三个操作数:内存值V、旧的预期值A、要修改的值B,当且仅当预期值A和内存值V相同时,才会将内存值修改为B并返回true,否则什么都不做并返回false。当然CAS一定要volatile变量配合,这样才能保证每次拿到的变量是主内存中最新的那个值,否则旧的预期值A对某条线程来说,永远是一个不会变的值A,只要某次CAS操作失败,永远都不可能成功。
Condition就是一接口,而在AQS 中的ConditionObject内部类实现了这个接口。Condition接口中只是进行了一些等待和通知方法的声明,并没有进行实现,Condition 经常可以用在生产者-消费者的场景中,关于Condition相关的东西,我们需要先了解AQS相关的知识,可以看看之前的那篇文章:Java 并发 - AQS:框架分析,然后再进行Condition的了解
这里先讲一句:Condition 中的方法则要配合锁对象使用,并通过newCondition方法获取实现类对象。这有点像Object 中的方法需要配合 synchronized 关键字使用。关于Condition与Object类实现的这些方法可以看这篇文章中最下面的那个对比,Ojbect类的wait(), notify() 或 notifyAll() 方法是基于对象的监视器锁的,我们现在所讲的Condition是基于 ReentrantLock 实现的,而ReentrantLock 是依赖于 AbstractQueuedSynchronizer 实现的。
在这阶段的学习过程中我会先抛出一系列:线程如何创建?这是一个很关键的问题,并发的关键在于多线程,那么如何创建线程呢?大概有几种方式呢?这几种方式的区别是什么?什么情况下应该使用这种创建方式?什么时候又不应该呢?那么具体的过程应该是如何呢?是否应该给出一两个例子会更好的说明一下?
问题太多,搞得自己都乱了,最主要的还是要一点点的去了解,最后串成一根线,才能更好对知识的进行掌握。
我想应该将这几种方式联系起来做一个对比,这样才能更好的理解这些创建线程方式的优点与缺点。
按照现有的认识,总的来说有两种实现线程的方式:
其实按照我的理解的话,详细分一下的话可以分为三种,就是继承Thread类,实现Runnable接口,实现Callable接口(虽然其内部也是实现Runnable接口),主要就是实现Runnable接口没有返回值,而实现Callable接口可以有返回值,所以也可以按照这三种方式去思考实际开发过程中到底需要哪种创建方式。
如果我们设置的线程池数量太小的话,如果同一时间有大量任务/请求需要处理,可能会导致大量的请求/任务在任务队列中排队等待执行,甚至会出现任务队列满了之后任务/请求无法处理的情况,或者大量任务堆积在任务队列导致 OOM。这样很明显是有问题的! CPU 根本没有得到充分利用。
但是,如果我们设置线程数量太大,大量线程可能会同时在争取 CPU 资源,这样会导致大量的上下文切换,从而增加线程的执行时间,影响了整体执行效率。
注:上下文切换的解释
需要肯定的一点是:线程池肯定是不是越大越好。
线程池(Thread Pool)是一种基于池化思想管理线程的工具,经常出现在多线程服务器中,如MySQL。
线程池可以简单看做是一组线程的集合,通过使用线程池,我们可以方便的复用线程,避免了频繁创建和销毁线程所带来的开销。在应用上,线程池可应用在后端相关服务中。比如 Web 服务器,数据库服务器等。以 Web 服务器为例,假如 Web 服务器会收到大量短时的 HTTP 请求,如果此时我们简单的为每个 HTTP 请求创建一个处理线程,那么服务器的资源将会很快被耗尽。当然我们也可以自己去管理并复用已创建的线程,以限制资源的消耗量,但这样会使用程序的逻辑变复杂。好在,幸运的是,我们不必那样做。在 JDK 1.5 中,官方已经提供了强大的线程池工具类。通过使用这些工具类,我们可以用低廉的代价使用多线程技术。
线程过多会带来额外的开销,其中包括创建销毁线程的开销、调度线程的开销等等,同时也降低了计算机的整体性能。线程池维护多个线程,等待监督管理者分配可并发执行的任务。这种做法,一方面避免了处理任务时创建销毁线程开销的代价,另一方面避免了线程数量膨胀导致的过分调度问题,保证了对内核的充分利用。
通过前面的AQS的基本原理了解:之后:Java 并发 - AQS:框架分析,我了解了大概的AQS的一整个流程,也明白了大部分的同步工具都是基于AQS来实现的,好像比较重要的就是重写tryAcquire 和 tryRelease 两个方法而已,那么我借鉴了其他同步工具的写法,试了试尝试自己实现一个基于AQS的同步工具,看看能不能正常跑起来。
以下是基于独占式的写法,并不是共享式的,所以实现的也是tryAcquire和tryRelease。主要想做的事情就是同一个时刻只能让一个线程一直抱有资源做一件事情,直到这件事情做完了之后,才可以让其他线程去做一些事情,这不就是同步的概念嘛!
对于一个线程要如何去停止呢?还有不同情况下的线程要如何停止呢?停止一个线程是什么意思?就是让这个线程在它进行任务处理的时候进行停止,停掉当前的操作,之前有学习到一个Thread.stop()方法,好像已经被废弃了,是不安全的一个方法,那么除了这个方法,还有其他什么办法吗?
总的来说,Java有如下几种方法去停止线程:
sleep()函数的时间范围内被interrupted就会中断线程,置状态位为false并抛出sleep interrupted异常。关于HashMap 其实还是有很多困惑的,学习了这么长时间,一边记录遇到的一些问题,一边整理笔记,如下所示。
关于HashMap 的底层数据结构,我有以下这么几个疑问,当时也是查看书籍和百度谷歌了好一会儿,然后连带着寻找到其他的一些问题,如下。
关于底层数据结构为什么采用 数组+链表 这么一种组合的几个问题:
Entry[] table = new Entry[capacity];List<Entry> table = new LinkedList<Entry>();AbstractQueuedSynchronizer (抽象队列同步器,以下简称 AQS)出现在 JDK 1.5 中,AQS 这个东西在Java的并发中是很重要的一部分,因为他是很多同步器的基础框架,比如 ReentrantLock、CountDownLatch 和 Semaphore 等等都是基于 AQS 实现的。基于AQS来构建同步器可以带来很多好处。它不仅能够极大地减少实现工作,而且也不必处理在多个位置上发生的竞争问题。
在基于AQS构建的同步器中,只能在一个时刻发生阻塞,从而降低上下文切换的开销,提高了吞吐量。同时在设计AQS时充分考虑了可伸缩行,因此J.U.C中所有基于AQS构建的同步器均可以获得这个优势。
AQS的主要使用方式是继承,子类通过继承同步器并实现它的抽象方法来管理同步状态。
AQS使用一个int类型的成员变量state来表示同步状态,当state>0时表示已经获取了锁,当state = 0时表示释放了锁。它提供了三个方法(getState()、setState(int newState)、compareAndSetState(int expect,int update))来对同步状态state进行操作,当然AQS可以确保对state的操作是安全的。
AQS通过内置的FIFO同步队列(这个会重点分析一下)来完成资源获取线程的排队工作,如果当前线程获取同步状态失败(锁)时,AQS则会将当前线程以及等待状态等信息构造成一个节点(Node)并将其加入同步队列,同时会阻塞当前线程,当同步状态释放时,则会把节点中的线程唤醒,使其再次尝试获取同步状态。
一句话:AQS使用一个Volatile的int类型的成员变量来表示同步状态,通过内置的FIFO队列来完成资源获取的排队工作,通过CAS完成对State值的修改。